

Bạn đã nghe về Code Combat Rift mới nhất chưa? Nếu bạn muốn trải nghiệm trò chơi nhập code hấp…

Code Cyber DigiFusion mới nhất – Bạn đã bao giờ muốn nhận được những quà tặng có giá trị trong…

Bạn có muốn cập nhật mã code Cửu Vĩ Đại Chiến Mobile mới nhất và biết cách sử dụng chúng?…
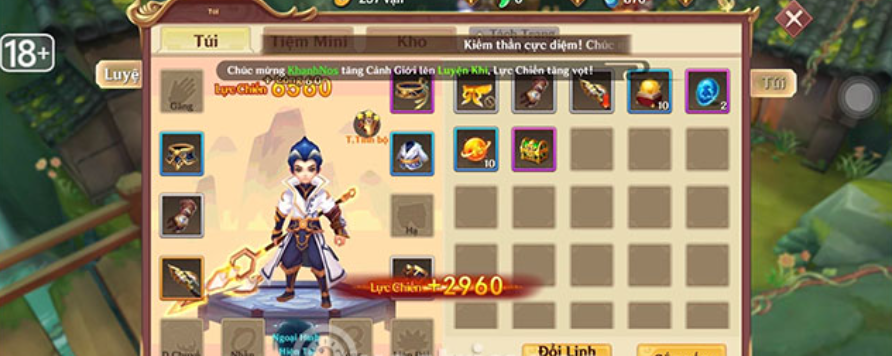
Code Cửu Thiên Mobile mới nhất – Cửu Thiên Mobile là một trò chơi nhập vai nổi tiếng do NPH…
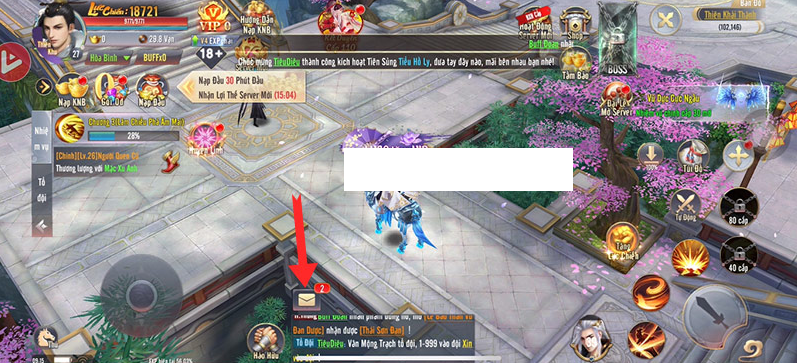
Code Cửu Mộng Tiên Vực mới nhất – Cửu Mộng Tiên Vực Mobile là một trò chơi nhập vai MMORPG…
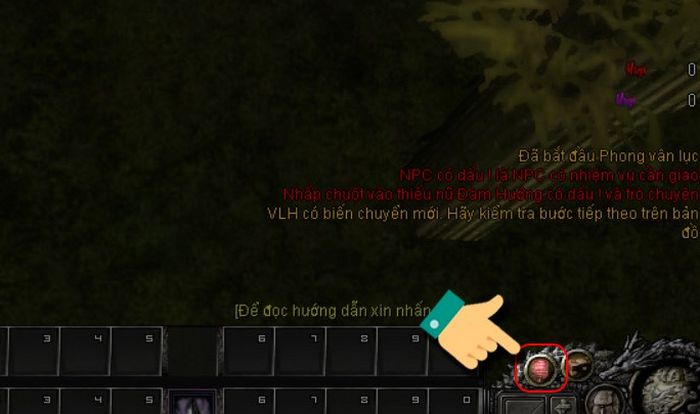
Bạn đang tìm kiếm về Code Cửu Long Tranh Bá mới nhất hiện nay? Cửu Long Tranh Bá là một…

Bạn đã biết về code Đại Lộ Danh Vọng mới nhất 2023 và cách nhập code chưa? Nếu bạn là…

Bạn đã bao giờ tò mò về những mã code Đai Hoang Phong Thần Lục ? Hãy cùng triple-hearts khám…

Bạn có muốn khám phá những code đại hiệp truyện mới nhất? Từ những mã này, bạn có thể nhận…

Bạn đang quan tâm đến vấn đề code Đại Chúa Tể mới nhất năm 2023 và cách nhập code? Code…

Bạn muốn tìm kiếm những mã code đại chiến tân thế giới mobile mới nhất? Hãy đến với bài viết…

Bạn đang tìm kiếm các mã code Đại Chiến Tân Thế Giới mới nhất năm 2023? Hãy cùng triple-hearts khám…
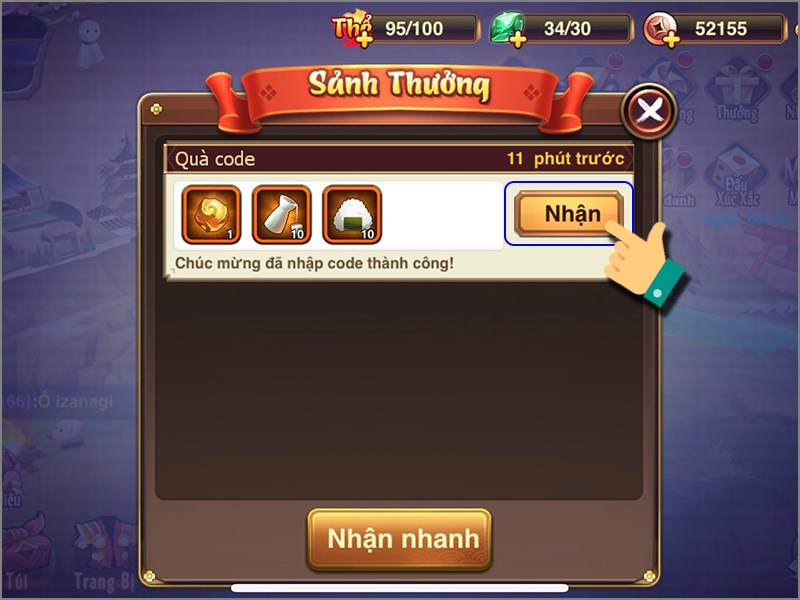
Bạn đang tìm kiếm thông tin về code đại chiến Samurai mới nhất năm 2023? Đúng chỗ rồi! Trong thế…

Bạn là một người yêu thích game Đại Chiến Nhẫn Giả? Bạn không muốn bỏ lỡ bất kỳ mã code…

Bạn đã sẵn sàng để khám phá những mã code Da Hood mới nhất? Đừng bỏ qua cơ hội tận…

Bạn có muốn khám phá các code cyber fantasy tân giới viễn tưởng mới nhất năm 2023? triple-hearts đã tổng…

Nếu bạn là một fan của trò chơi Roblox và đặc biệt là trò chơi Chrono Piece, thì bạn không…

Bạn đã muốn khám phá mã code mới nhất của Code Cực loạn 3Q mới nhất và muốn biết cách…

Bạn muốn khám phá code cube defense mới nhất và muốn biết cách nhập code cube defense? Code Cube Defense…

Bạn có muốn khám phá code simulator mới nhất về nam châm biến đổi công nghệ và cách nhập mã…
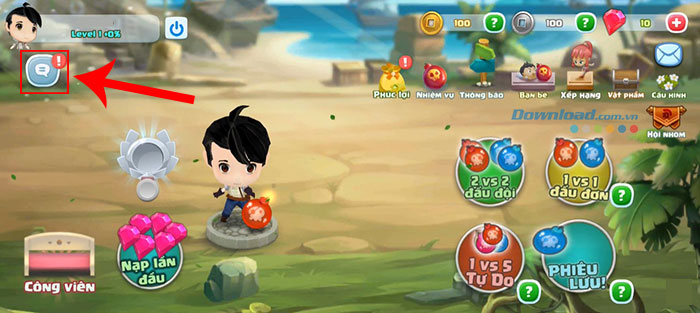
Bạn có muốn khám phá code Crazy Boom mới nhất và biết cách để nhập code Crazy Boom không? Crazy…

Bạn muốn khám phá code Cờ võ hiệp mới nhất và để biết cách nhập code Cờ võ hiệp? Code…

Bạn muốn khám phá code counter side mới nhất và biết cách nhập code counter side? Code counter side là…

Bạn có muốn khám phá code cookie run ovenbreak mới nhất của trò chơi Cookie Run Ovenbreak và biết cách…

Bạn đã nghe về Code Cookie Run Kingdom mới nhất chưa? Nếu bạn muốn khám phá những code mới nhất…

Chúng tôi sẽ cung cấp danh sách mã code Chrono Legacy mới nhất để nhận phần thưởng. Bài viết cũng…
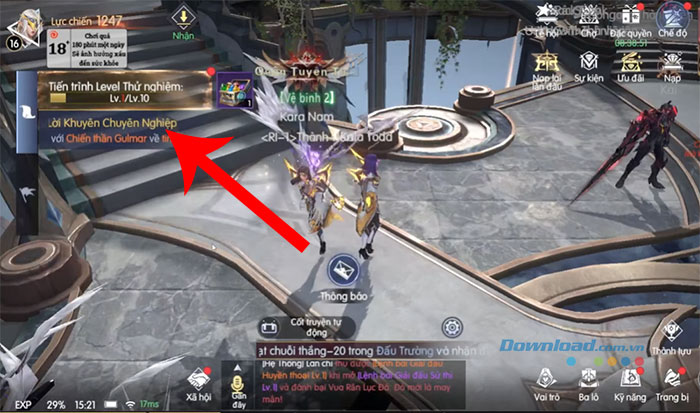
Bạn đã từng tìm kiếm một trò chơi ARPG thú vị với đồ họa đẹp và trải nghiệm chiến đấu…
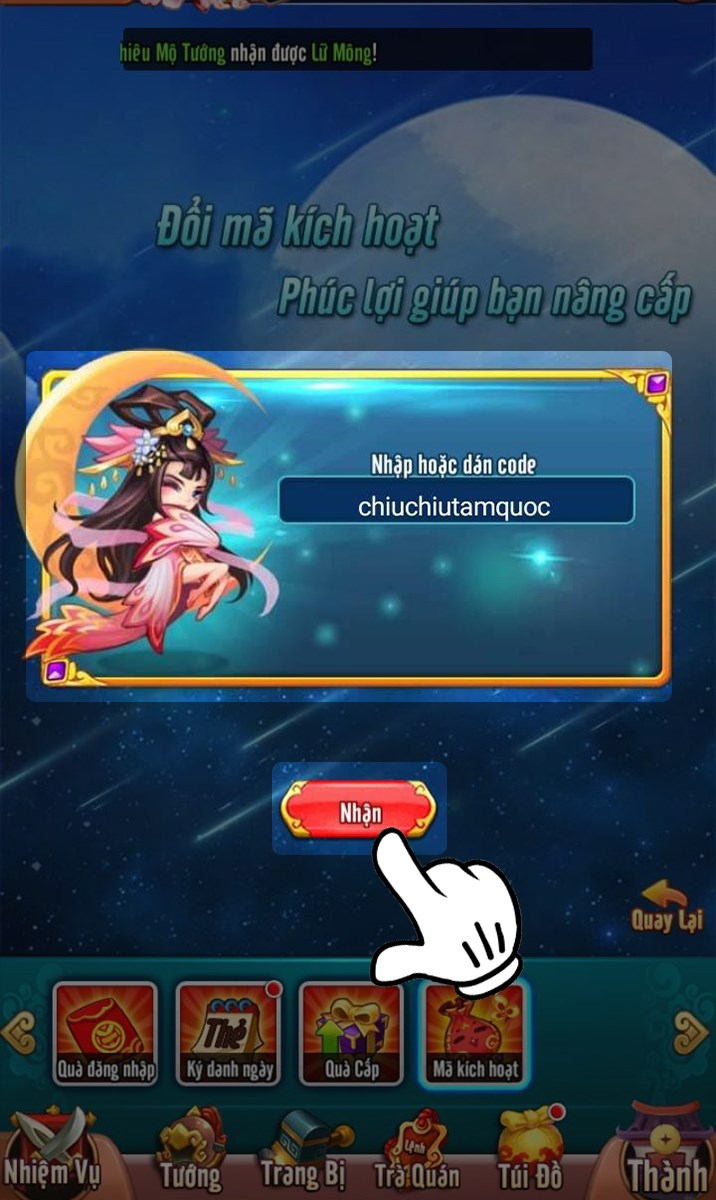
Danh sách mã code Chiu Chiu Tam Quốc mới nhất đã công bố. Để nhập mã code, bạn cần hoàn…
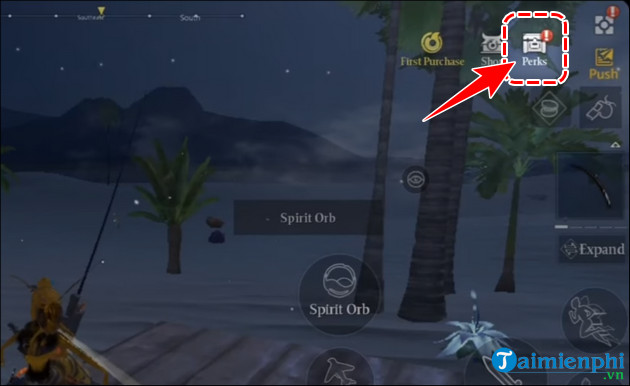
Bạn đang tìm kiếm những cách để nâng cao khả năng chiến đấu và tích luỹ tài nguyên trong thế…
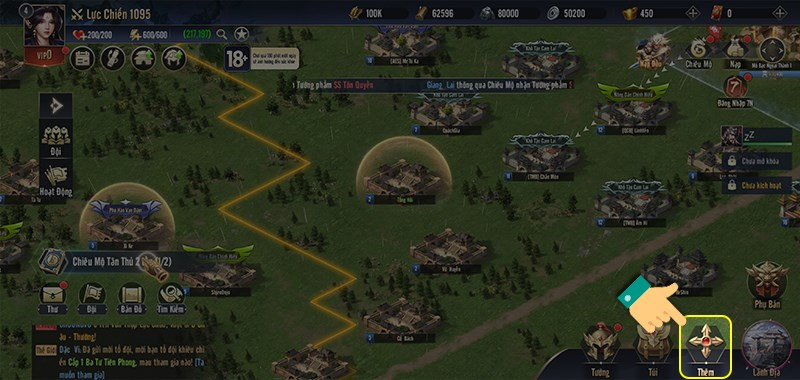
Bạn đang chơi game Chiến Vương Tam Quốc và muốn nhận được nhiều phần thưởng hấp dẫn? Bài viết này…
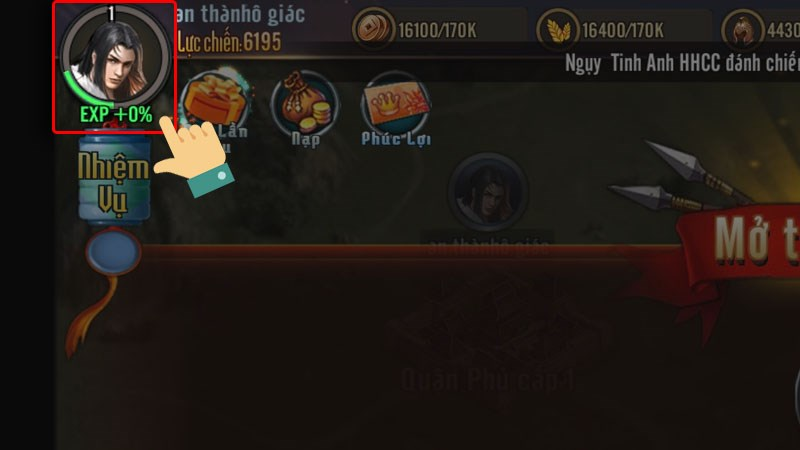
Nếu bạn là fan của game Chiến Tướng Tam Quốc, hãy chuẩn bị sẵn sàng với những mã code Chiến…
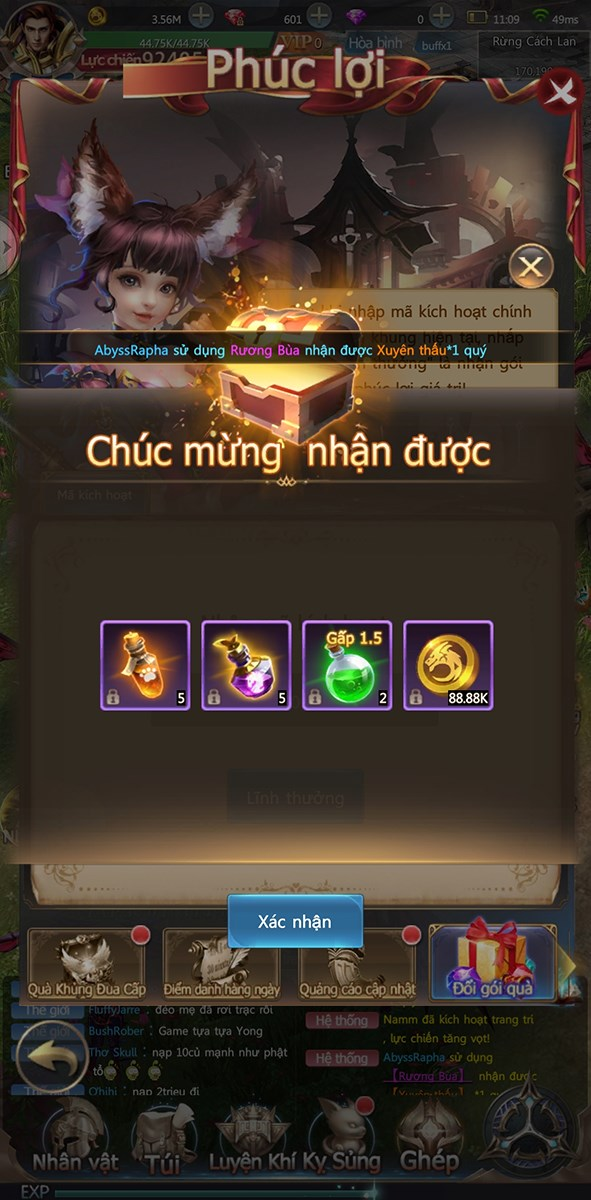
Bạn đã từng nghe nói về Code Chiến Thần Thức Tỉnh mới nhất chưa? Đó là những mã quà tặng…
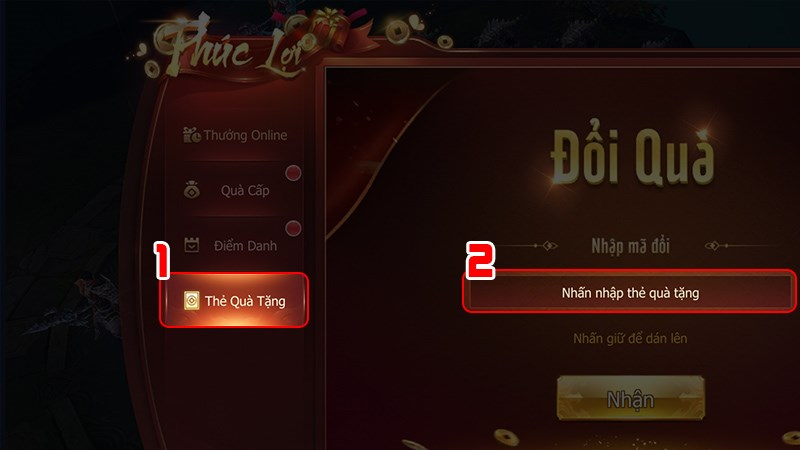
Bạn đang chơi game Chiến Thần Kỷ Nguyên và đang tìm kiếm các mã code Chiến Thần Kỷ Nguyên mới…

Hãy khám phá trò chơi Chiến Thần AFK, một tựa game đang gây sốt tại thị trường Đông Nam Á.…

Code Combat Warriors mới nhất là một tựa game nhập vai mới trên Roblox thu hút sự quan tâm của…

Code Cửu Dương Truyền Kỳ 2 Mobile mới nhất – Nhập vai vào thế giới võ học cổ đại và…

Bạn muốn tìm hiểu về Tổng hợp Code Cửu Âm Chân Kinh mới nhất? Cửu Âm Chân Kinh là một…

Bạn đang tìm kiếm về các code Cursed Bride A Gothic Fantasy mới nhất? Cursed Bride: A Gothic Fantasy là…

Mã Code Cuộc Chiến Sinh Tồn mới nhất do NPH GGames phát hành đã sẵn sàng mang đến những phần…

Bạn đang tìm kiếm những Code Cung Đình Kế Mới nhất? Trải nghiệm cuộc sống trong cung đình, khám phá…

Khi bạn tham gia Cổ Long Kiếm, bạn sẽ có cơ hội trở thành một trong những nhân vật Thần…

Cổ kiếm Mobile là một tựa game kiếm hiệp và tu tiên hấp dẫn, với đồ họa 3D tuyệt đẹp.…

Muốn trở thành siêu anh hùng và kiếm được nhiều xu trong trò chơi “Coins Hero Simulator” phiên bản mới…

Bạn đang đọc bài viết Tổng hợp Mã code animiya afk epic battles Mới Nhất và Hướng dẫn nhập mã…

Hôm nay, triple-hearts sẽ cung cấp cho bạn danh sách các mã code Clover Knights Thánh Hiệp Sĩ Mới Nhất.…

Gần đây, nhà phát hành VNG đã tung ra một trò chơi phiêu lưu mới có tên Cloud Song: Vân…

Bạn đang tìm kiếm mã code Clash of Zombies 2 mới nhất để nhận được phần thưởng hữu ích trong…

Hôm nay mình sẽ chia sẻ với các bạn về bộ mã Code clash of warpath wild rift Mới Nhất…

Bạn đã sẵn sàng nhận mưa Code clash of minions Mới Nhất chưa? Nhập ngay mã quà tặng mới nhất…

Với một đồ họa đẹp mắt, chân thực và hơn 100 nhân vật Ninja, Chưởng Thượng Tu Tiên đã tái…